Распределеннаядиагонализация.
В комбинаторике есть понятие т.н. "комбинаторноговзрыва", когда с ростом размерности задачи ее вычислительная сложностьрезко возрастает и применение ряда методов, работавших до этого для малыхразмерностей, становится невозможным из-за необходимости огромныхвычислительных затрат. На примере решаемых в настоящее время задач, связанных спостроением спектров, данная ситуация для диагонализации и поквадратного обходаокрестностей начинает проявляться на размерности N=13. И если диагонализациюеще можно реализовать по частям (что и было сделано), то поквадратный обход дляданной окрестности уже невозможен (приблизительная оценка необходимыхвычислительных затрат — 80 лет в проекте), следовательно, мы пойдем другимпутем :).
В решаемых в настоящее время задачах, связанных с построениемспектров, диагонализация применяется совместно с анализом окрестностей ипозволяет как увеличить мощность результирующего спектра, так и сдвинуть еговерхнюю и нижнюю границы в ситуациях, когда спектр близок к пределу и просто обходомокрестностей границы уже не сдвигаются (это не единственное применениедиагонализации, остальные пока оставим в стороне). Для размерности N=12диагонализация уже выполнялась от нескольких часов до нескольких десятков часовна квадрат (для рекордсмена по числу трансверсалей — более недели в 1 поток намоей машине), для текущей размерности N=13 самые легкие квадраты будутдиагонализироваться несколько часов, тяжелые — до нескольких месяцев, чтонеприемлимо. Поэтому, пользуясь свободным временем, в коде был реализованраспределенный вариант диагонализатора, который давно созрел в голове и ждал,когда же его наконец реализуют... 🙂
В двух словах диагонализация выполняется следующим образом: измножества трансверсалей ЛК находятся подходящие пары трансверсалей, по которымпроизводится ряд целенаправленных перестановок строк и столбцов исходного ЛК сцелью получения результирующего ДЛК с интересными свойствами, что сильнобыстрее (на много порядков) лобовой перестановки всех возможных пар строк истолбцов.
Далеко не все пары трансверсалей являются интересными, однакопроверять необходимо все, при этом пары (T[i], T[j]) и (T[j], T[i]) проверятьдважды смысла нет, что при изображении соответствия трансверсалей в видебинарной матрицы (0 — не подходят, 1 — подходят) приводит к необходимостиобхода не всей матрицы, а ее половины — верхней или нижней треугольнойподматрицы (для определенности обходится верхняя). В программировании этообычное дело, применяется очень часто в ряде алгоритмов, псевдокод выглядит примернотак:
for (int i = 0; i <NT; i++)
for (int j = i+1; j< NT; j++)...
Если код работает долго, значит его необходимо разбивать на кускии запускать их параллельно (в нашем случае — распределенно в проекте попринципу "1 кусок — 1 WU'шка"). Простейшим способом распараллеливанияявляется разбиение по внешнему циклу (по i), однако здесь есть проблема: втаком случае в каждой WU'шке потребуется хранить полное множество трансверсалей(для порядка N=13 их уже бывает более миллиона, для бОльших порядков их будетсильно больше, см.
https://oeis.org/A287644), что потребует минимум сотен МБ —единиц-десятков ГБ оперативной памяти на WU.
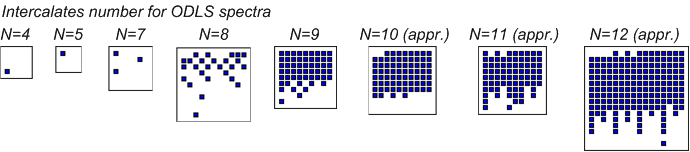
Более подходящей видится следующая стратегия: матрица разбиваетсяна квадраты заданного размера K x K, одна WU'шка производит обработку одногоквадрата (см. рис., на нем изображен один из самых легких ДЛК с 43 тыс.трансверсалей и разбиение на WU'шки по 20 тыс. x 20 тыс. трансверсалей вквадрате, всего 6 WU'шек). При этом возникает ряд нюансов, но они терпимые илегко реализуются в коде. К ним относятся:
* необходимость построения разбиения на квадраты, некоторые изкоторых частично попадают под главную диагональ (на рисунке изображеныоранжевым) — в составе соответствующих WU'шек необходима проверка и отсечениепар трансверсалей из нижней треугольной подматрицы (красные квадраты ипрямоугольники обрабатываются полностью);
* наличие маленьких прямоугольников и квадратов по краям (им будутсоответствовать более короткие WU'шки с рядом дополнительных проверок, чтобы невылезти за пределы анализируемой области вправо и вниз);
* обходимость хранения множества трансверсалей по кускам (точнее,в два куска в диапазонах [x; x+K] и [y; y+K], (x,y) — координаты верхнеголевого угла анализируемого квадрата/прямоугольника, диапазоны иногда могут пересекаться(в данной задаче — совпадать полностью, в перспективных задачах поэвристической работе со спектрами — частично пересекаться)).
Неоспоримым плюсом подхода является его универсальность: наквадраты можно разбить как легкие, так и тяжелые ДЛК, в последнем случае простоквадратов будет больше (для топового ДЛК порядка 13 — около 2500 при текущемразбиении), возможно управлять средним временем счета WU'шек и затратами памятипутем изменения размера квадрата K (критичным в данной задаче является именновремя счета, которое в проекте не желательно делать как сильно маленьким(минуты и меньше), так и сильно большим (десятки часов), затраты памятиприемлемые).
Кроме описанного выше распараллеливание также сделано попарастрофическим преобразованиям (по 3 на ДЛК из 6 возможных, транспонированиеисключено, т.к. оно дает ДЛК из того же главного класса и не интересно) и т.н.slice'ам для каждого из них (тоже 3, итого 9 комбинаций), в данном случае всетривиально в плане распараллеливания.
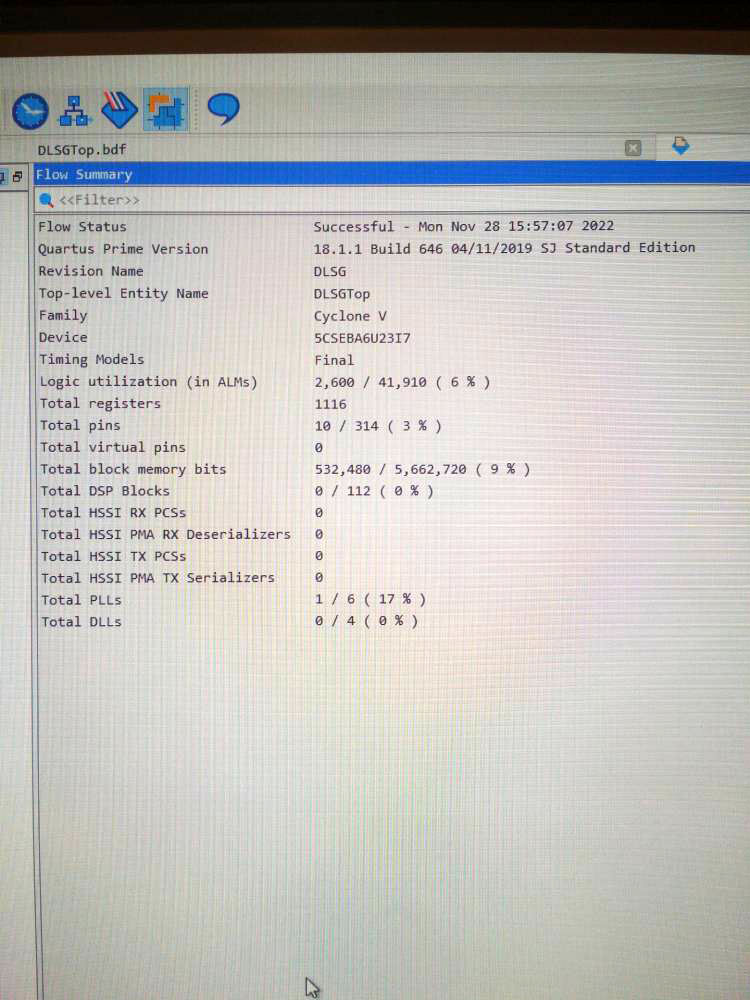
Вчера в проект была добавлена новая версия расчетного модуля свключенным рядом отладочных проверок и чуть более чем 10 тыс. WU'шек для 200наиболее легких ДЛК с целью тестирования корректности кода и анализа затратвремени. В настоящее время выполняется досчет хвостов, после чего можно будетприступать к более подробному анализу, однако уже сейчас видно, что вроде всеболее-менее норм. Среднее время счета у меня на Core i7 4770 было в районе 7-8минут, максимальное — около 20 минут для K=20000. В перспективе K будет немногоувеличено, WU'шки немного потяжелеют и расчет будет запущен в боевом режиме.Досчитываем хвосты и считаем другие подпроекты...
PS. Применение распределенной диагонализации отнюдь неограничивается рассмотренным выше экспериментом, который мы будем выполнять вближайшие недели. В перспективе оно планируется к использованию как для сдвигаверхних и нижних границ для некоторых оценок, так и в составе следующей серииэвристических алгоритмов расширения текущих спектров, когда текущая серияотработает и спектры перестанут меняться.
PPS. При организации подобного распределенного расчета в грид естьеще один нюанс, связанный с построением необходимого множества трансверсалей.Его можно однократно получить в процессе генерации WU'шек, а затем передать наклиент, а можно получить первым этапом при счете WU'шки.
В данном экспериментевыбран первый вариант (на генерацию нужных трансверсалей теряем 1-2 секунды вкаждой WU'шке, зато экономим несколько сотен КБ исходных данных WU'шки (а онисперва генерируются, потом хранятся в одной из таблиц БД на сервере проекта,затем передаются на клиент, копируются/мапятся в папку слота при стартерасчета)). В перспективе с ростом размерности вполне вероятна ситуация, вкоторой получение нужных подмножеств трансверсалей подобным образом в каждойWU'шке станет неприемлемо долгим и придется перейти ко второму варианту...
Хотите принять участие в распределенных вычислениях, тогда, Вамсюда:
https://boinc.berkeley.edu/wiki/Simple_view
https://boinc.berkeley.edu/download_all.php
https://boinc.ru
Ссылка на git-хаб, где лежат исходники программы-клиента BOINC.
https://github.com/BOINC/boinc












 Имя и пароль
Имя и пароль
 Если сравнивать с ценой мака...
Если сравнивать с ценой мака...
 Быстрая навигация
Быстрая навигация

 Главная
Главная